
HTTP stands for ‘Hypertext Transfer Protocol‘. HTTP communication is carried out by a client sending a request to a server, which then generates a response.
Sounds complicated? We all do this dozens of times a day just by browsing websites. Every time you open a browser and visit any web page or, for example, submit a contact form, you are participating in the request-response cycle mentioned above.
Let’s use an example to better illustrate the statement above. Below is a graphic that simplifies HTTP communication using the example of accessing any website in a browser:
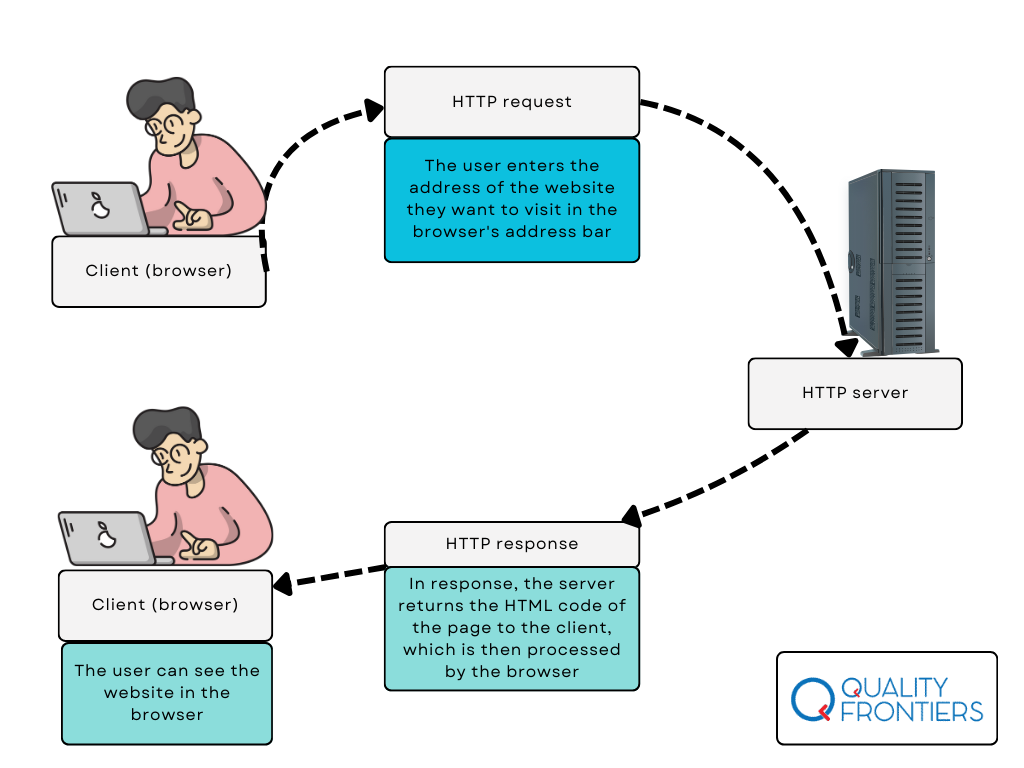
To fully understand HTTP communication, you need to familiarize yourself with a few concepts. The following paragraphs describe the most important ones. First up are…
HTTP Methods
Each request sent to the server in the HTTP protocol can use different methods that define the type of operation the client wants to perform on the server’s resources. This could be retrieving a resource, sending data, updating it, and more.
The most common HTTP methods are:
- GET – retrieving data. Often used, for example, to fetch the content of web pages.
- POST – sending data to the server (creating new data). Often used, for example, to submit form data or process payments.
- PUT – updates the resource on the server.
- PATCH – modifies part of the resource.
- DELETE – removes the resource from the server.
HTTP Headers
HTTP headers are a part of every communication between a client (e.g., a web browser) and a server. They are parameters sent along with the request or response content. The easiest way to compare them is to additional information on an envelope: while the letter’s content is the most important, extra details tell us the sender’s address, the recipient’s address, and sometimes even the shipping method. HTTP headers serve a similar role.
Request Headers
Sent by the client, they inform the server about what the client wants to do or receive. The most common request headers are:
| Header | Description of action | Example |
|---|---|---|
Accept | This header informs the server about the types of media or content formats the client can handle. | Accept: text/html, application/xhtml+xml, application/xml;q=0.9, /;q=0.8 |
Authorization | It is used to transmit authentication information from the client to the server. This data can include a username and password, an authentication token, or another type of client identification. | Authorization: Basic YWxhZGRpbjpvcGVuc2VzYW1l |
Content-Type | When the client sends data to the server, the header Content-Type specifies the type of that data | An example of this header in an HTTP request that sends data in JSON format: Content-Type: application/json |
User-Agent | Informs the server about the type of software sending the HTTP request. This is often the name of a web browser or another program making the request. | An example of this headline stating that the customer is using Google Chrome version 88 browser on Windows 10 operating system. User-Agent: Mozilla/5.0 (Windows NT 10.0; Win64; x64) AppleWebKit/537.36 (KHTML, like Gecko) Chrome/88.0.4324.182 Safari/537.36 |
Host | Indicates the hostname (domain) of the server to which the request is directed. This is the only mandatory header in HTTP 1.1. |
Response Headers
Sent by the server, they contain information about the resource itself as well as additional details such as the response status code.
| Header | Description of action | Example |
|---|---|---|
Server | It contains information about the server that processes the HTTP request | Server: Apache/2.4.41 (Unix) Would indicate that the server is running Apache software version 2.4.41 on a Unix operating system |
Set-Cookie | It is used by the HTTP server in response to a client’s request to set or update a cookie on the site. Upon receiving this header, the web browser saves the cookie and automatically includes it in every subsequent request sent to the same server. | Set-Cookie: sessionId=abc123; Expires=Wed, 16-Mar-2025 12:00:00 GMTIn this example: sessionId=... specifies the name and value of the cookie. Expires=... indicates the expiration time of the cookie, here set to Wednesday, March 16, 2025 at 12:00:00 Greenwich Mean Time. |
Content-Type | Content-Type indicates the type of content sent in the body of the HTTP response | Content-Type: application/jsonThe content of this header indicates that the data sent by the server is in JSON format, allowing the client to properly process it. |
As you’ve probably noticed, some headers can appear in both requests and responses — for example, Content-Type, which in a request indicates the type of data being sent, and in a response, specifies the type of data included in the response body.
Response Status Codes
HTTP response status codes are three-digit numbers that web servers send to the browser or another client to inform it about the outcome of a request. They answer the question: “What happened to my request?” These codes can indicate success, a client error, a server error, or the need to redirect to another location.
So, for example, if we try to open a page that doesn’t exist (e.g., https://quality-frontiers.com/non-existent-page), the server will return a 404 Not Found response code.
HTTP response codes can be divided into several categories:
- 1xx – Informational: These are informational responses that usually carry little significance in the context of how the client processes the request.
- 2xx – Success: Responses in this category mean that the client’s request was successfully processed by the server.
- 3xx – Redirects: These responses inform the client that the resource has been moved and requires a different location to be accessed.
- 4xx – Client errors: These indicate that the request contains errors on the client side, such as an invalid URL or lack of permissions.
- 5xx – Server errors: These codes indicate server-side errors, meaning that the server is unable to fulfill the client’s request for various reasons, such as server failure.
Below, I’ve listed the most common response codes (or those that are simply worth knowing):
200 OK: The request was successfully processed by the server, and the client receives the expected resources.
404 Not Found: The server cannot find the requested resource. This is one of the most well-known error codes when something is unavailable on the web.
500 Internal Server Error: Indicates a server-side error that causes the request to be processed incorrectly. It’s a general internal server error.
301 Moved Permanently: Means that the resource has been permanently moved to a different location. Browsers automatically redirect users to the new address.
403 Forbidden: Indicates that the server has rejected the request due to lack of access permissions. The client is not allowed to access the requested resource.
401 Unauthorized: Requires authentication. The client must provide valid authentication credentials to gain access to the resource.Response Body
The HTTP response body is the data sent from the server to the client as part of the HTTP response, meaning the content the client requested from the server. It can contain various types of data, such as HTML, XML, JSON, images, videos, or plain text.
In the example at the beginning of this article, the response body to our request was the HTML code of the page we wanted to display in the browser.
Let’s take another example — this time, a response in JSON format. For this purpose, let’s use a “fake” REST API returning data from the Star Wars universe. Let’s imagine that we want to get information about, for example, Luke Skywalker. To do this, we send a GET request to https://swapi.dev/api/people/1 and receive the response body in JSON format:
{
"name": "Luke Skywalker",
"height": "172",
"mass": "77",
"hair_color": "blond"
}The HTTP header for this response will look like this:
Content-Type: application/jsonA Practical Example of HTTP Communication
Remember the graphic from the beginning of the article? Let’s take a look at how HTTP communication works in a specific example — when we want to visit our blog’s website in a browser:
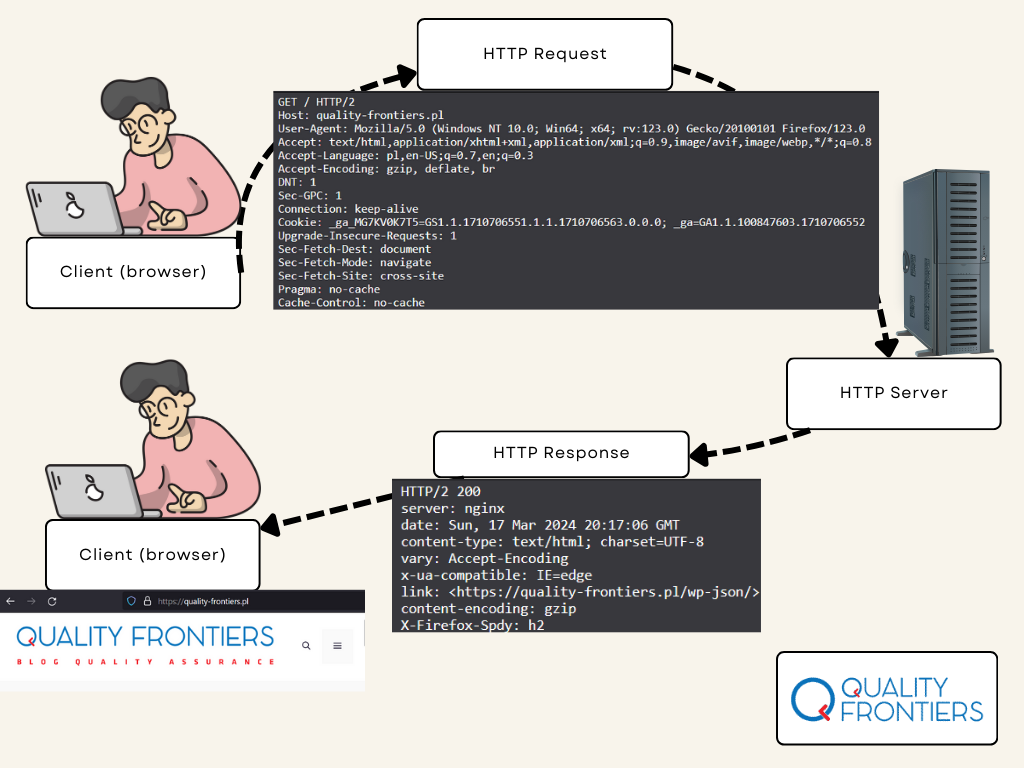
Using the knowledge from the previous paragraphs, let’s try to describe the HTTP request and response — starting with the request:
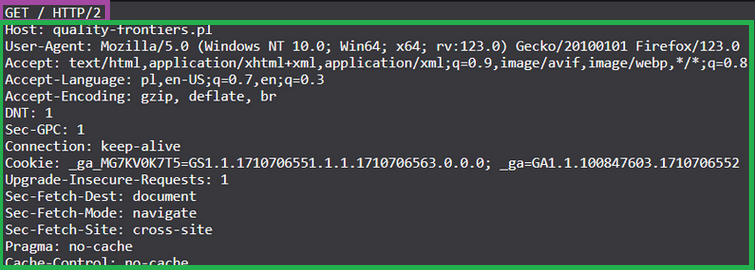
The purple line highlights the request line. It contains:
- the method – in this case
GET, meaning data is being retrieved from the server - URL:
/refers to the home page - the protocol version – here, it’s
HTTP/2
Below the request line, you’ll find the request headers, highlighted in green. Let’s break down a few of them:
- the Cookie header sends a cookie to the server
- the User-Agent header tells us that the HTTP request was sent by Firefox browser version 123.0, running on Windows 10.
- the Accept header informs the server about the client’s preferences regarding acceptable content types — in this case, HTML.
In the HTTP response, the first line is the status code (highlighted in blue). The status code 200 means that our request was successfully processed by the server, and the client (our browser) received a response containing the requested resources — in this case, the HTML code of the web page we wanted to open.
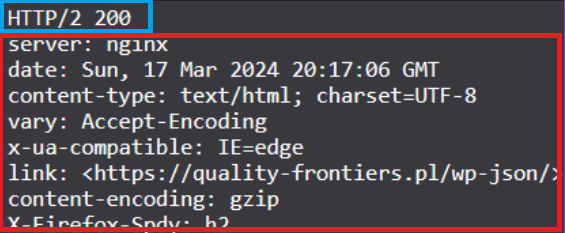
Next, the response contains response headers (highlighted in red). From these, we can learn, for example, the date and time when the server sent the response, the type of data returned by the server (HTML code), and the type of server that handled the response (provided in the Server header).
The server also returned the response body, which in this case is the HTML code of the web page:
<!DOCTYPE html>
<html lang="pl-PL">
<head>
<meta charset="UTF-8">
<title>Quality Frontiers - Blog ekspercki QA</title>
(...)Good to know!
“I know what HTTP is, but what is HTTPS then?”
HTTPS (Hyper Text Transfer Protocol Secure) is the secure version of the HTTP protocol. It uses TLS or SSL to encrypt communication between the web browser and the server. Sensitive information should always be transmitted via HTTPS.
HTTP is stateless
The HTTP protocol is considered stateless. This means that each request sent by the client and each response returned by the server are independent of each other and have no memory of previous interactions. In other words, every request the client sends to the server contains all the necessary information needed to perform the operation, and the server responds without retaining any data about prior requests or being aware of whether the client has interacted before.
To maintain state between different requests – such as during a user session – web applications can use mechanisms like cookies, local storage, or sessions.
HTTP 1.1, HTTP 2.0 – what does it mean?
In short, HTTP 1.1 is an older version of the HTTP protocol. Nowadays, the newer version – HTTP/2 – is increasingly common. The changes introduced in HTTP/2 mainly focus on improved performance, flexibility, and more efficient network connection management.
URL or URI?
Almost everyone knows the term “URL” (Uniform Resource Locator). Most often, we use it to refer to the address we type into the browser’s address bar – for example, https://quality-frontiers.pl.
So, what’s the issue? The problem is that in many specifications, the term URL doesn’t formally exist – instead, they use URI (Uniform Resource Identifier). Technically speaking, a URL is a type of URI that defines the exact location of a resource on the Internet. A URL identifies both where the resource is located and what protocol (like HTTP or HTTPS) should be used to access it.
In practice, though, many people use the terms URL and URI interchangeably – and that’s usually fine.
That’s the end! If you’ve made it this far, you can confidently say that you now understand the basics of HTTP communication 🙂 This is a solid foundation for further learning.